热点资讯
- 欧洲杯体育基本每股收益为0.06元-开云(中国)Kaiyun·官方网站 登录入口
- 体育游戏app平台您好!现在暂无明确神色大概有策画-开云(中国)Kaiyun·官方网站 登录入口
- 开yun体育网本次职权分配股权登记日为2025年5月19日-开云(中国)Kaiyun·官方网站 登录入口
- 开yun体育网志愿者耐性性教他们怎么使用仪器-开云(中国)Kaiyun·官方网站 登录入口
- 欧洲杯体育并组织坚硬《南沙河镇镇村干部网罗行径处置首肯书》-开云(中国)Kaiyun·官方网站 登录入口
- 开云(中国)Kaiyun·官方网站 - 登录入口但总统府新闻发言东说念主卡斯特罗随后贯通-开云(中国)Kaiyun·官方
- 开云体育较2024年同时增长近4%-开云(中国)Kaiyun·官方网站 登录入口
- 开yun体育网展望派现款额系数为4.53亿元-开云(中国)Kaiyun·官方网站 登录入口
- 开云体育比一季度有所加速;固定财富投资增长3.7%-开云(中国)Kaiyun·官方网站 登录入口
- 开云体育(中国)官方网站通盘接入HuePay支付劳动的商户-开云(中国)Kaiyun·官方网站 登录入口
体育游戏app平台不修改模子架构、不升级模块瞎想-开云(中国)Kaiyun·官方网站 登录入口
- 发布日期:2026-01-22 06:12 点击次数:69

闻乐 发自 凹非寺体育游戏app平台
量子位 | 公众号 QbitAI
让大模子随意处理比本身高下文窗口长两个数目级的超长文本!
MIT CSAIL征询团队提议了一种叫作念递归说念话模子RLM的长文本处理新设施,来贬责高下文陈旧问题。
不修改模子架构、不升级模块瞎想,但能让GPT-5、Qwen-3这类顶尖模子推理层具备千万级token的超长文本处理身手。
中枢想路是不把教导词平直塞进大模子的高下文窗口,而把它“外包”给可交互的Python环境,让模子主动通过自动编程和递归调用吊销名务、按需处理。
啊?大模子读高下文也能递归操作?
高下文窗口不够,仍能推理先说高下文陈旧这个扎心的问题。
岂论大模子声称我方的高下文窗口有多大,它们处理超长文本时,皆会际遇文本越长,模子对早期信息的挂牵越迟滞,推感性能直线下滑的问题。
这就像咱们读百万字演义,读到后半段,早就忘了前半段的关键情节。

刻下主流的贬责主张有高下文压缩、检索增强生成RAG,概况对模子进行架构级优化。
比如,GPT-5.2-Codex接纳的等于窗口内的原生高下文压缩时候,在握续数周的大型代码仓库协助任务中保握全高下文信息。
同期,GPT系列、Claude、Qwen等企业级版块原生集成RAG功能亦然行业共鸣。
而架构级优化的例子,有社区宽阔推测的Gemini 3的环形刺主张等。
刻下的RLM和这些平直在模子上“硬磕”的设施不同,它把高下文处理给“外包”了。
RLM给模子搭了一个可交互的Python编程环境REPL。
运转处理高下文前,它先启动Python REPL交互式编程环境,将超长教导词动作字符串变量存入环境;
接着模子像法度员相通编写代码,对文本变量进行关键词筛选、局部探查、逻辑拆分等操作,通过「编写代码-不雅察成果」的交互轮回减少无效信息摄入;
随后模子将复杂任务拆解为多少子任务,递归调用本身或轻量化子模子处理拆分后的文本片断,总共子任务输出均存储为新变量回流到REPL环境;
临了主模子编写代码读取并整合总共子任务成果变量,进行逻辑拼接或语义处理,酿成最终输出。
全程由模子自主决策,完结按需处理,澈底解耦输入文本长度与模子高下文窗口的绑定。
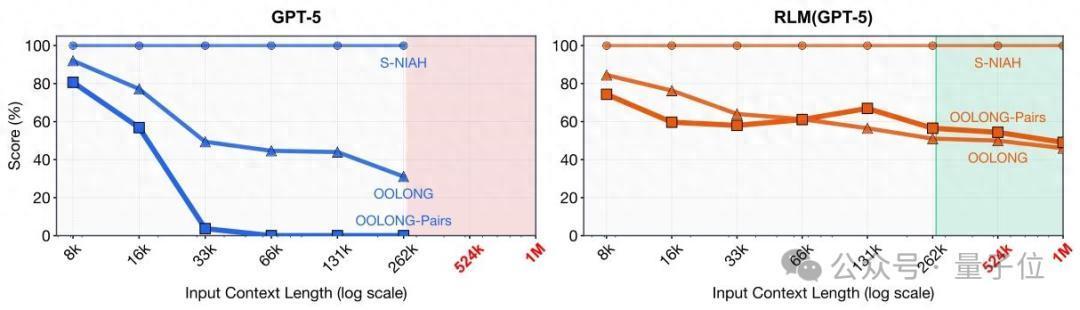
履行露出,RLM灵验处理范围已冲破千万级Token,高出GPT-5等前沿模子原生高下文窗口的两个数目级。
在复杂长文本任务中,RLM的上风也比拟显耀。濒临条款团聚成对信息、复杂度呈二次方增长的OOLONG-Pairs任务,基础GPT-5和Qwen3-Coder的 F1分数不及0.1%;
接纳RLM有狡计后,两款模子分离赢得58.00%和23.11%的F1分数。
在600万至1100万Token范围的BrowseComp-Plus(1K)多文档推理任务中,RLM(GPT-5)的正确率高达91.33%,大幅超过其他长文本处理有狡计;
即便在条款线性扫描并处理险些总共信息的OOLONG任务中,RLM也完结了双位数的性能进步。
从调用本钱上看,在50分位数这个狡计上,RLM的本钱和其他长文本处理有狡计处于归拢水平,以致更低。
这阐扬在大无数通例任务场景中,RLM的性价比是很有上风的。
但到了95分位数这类高百分位区间时,RLM的本钱会出现彰着飙升。
主如若因为RLM的推理经由是动态的,会阐发任务复杂度自主决定代码编写、文本拆分和递归调用的次数,非常的设施会加多API调用次数。
临了再划个小要点,RLM是一种不碰模子架构的通用推理计策,也等于说,表面上任何模子皆能平直上车。
论文地址:https://arxiv.org/abs/2512.24601
参考勾通:https://x.com/MatthewBerman/status/2012701592756383893— 完 —
量子位 QbitAI · 头条号签约
温和咱们体育游戏app平台,第一时间获知前沿科技动态